
 MaochengHu
576cda45b8
first commit
MaochengHu
576cda45b8
first commit
|
2 anni fa | |
|---|---|---|
| .. | ||
| _base_ | 2 anni fa | |
| legacy_model | 2 anni fa | |
| README.md | 2 anni fa | |
| README_cn.md | 2 anni fa | |
| README_en.md | 2 anni fa | |
| picodet_l_320_coco_lcnet.yml | 2 anni fa | |
| picodet_l_416_coco_lcnet.yml | 2 anni fa | |
| picodet_l_640_coco_lcnet.yml | 2 anni fa | |
| picodet_m_320_coco_lcnet.yml | 2 anni fa | |
| picodet_m_416_coco_lcnet.yml | 2 anni fa | |
| picodet_s_320_coco_lcnet.yml | 2 anni fa | |
| picodet_s_416_coco_lcnet.yml | 2 anni fa | |
| picodet_xs_320_coco_lcnet.yml | 2 anni fa | |
| picodet_xs_416_coco_lcnet.yml | 2 anni fa | |
README.md
简体中文 | English
PP-PicoDet

最新动态
- 发布全新系列PP-PicoDet模型:(2022.03.20)
- (1)引入TAL及ETA Head,优化PAN等结构,精度提升2个点以上;
- (2)优化CPU端预测速度,同时训练速度提升一倍;
- (3)导出模型将后处理包含在网络中,预测直接输出box结果,无需二次开发,迁移成本更低,端到端预测速度提升10%-20%。
历史版本模型
- 详情请参考:PicoDet 2021.10版本
简介
PaddleDetection中提出了全新的轻量级系列模型PP-PicoDet,在移动端具有卓越的性能,成为全新SOTA轻量级模型。详细的技术细节可以参考我们的arXiv技术报告。
PP-PicoDet模型有如下特点:
- 🌟 更高的mAP: 第一个在1M参数量之内
mAP(0.5:0.95)超越30+(输入416像素时)。 - 🚀 更快的预测速度: 网络预测在ARM CPU下可达150FPS。
- 😊 部署友好: 支持PaddleLite/MNN/NCNN/OpenVINO等预测库,支持转出ONNX,提供了C++/Python/Android的demo。
- 😍 先进的算法: 我们在现有SOTA算法中进行了创新, 包括:ESNet, CSP-PAN, SimOTA等等。

基线
| 模型 | 输入尺寸 | mAPval 0.5:0.95 | mAPval 0.5 | 参数量 (M) | FLOPS (G) | 预测时延CPU (ms) 预测时延Lite |
(ms) 权重下载 |
配置文件 |
导出模型 |
PicoDet-XS |
320*320 |
23.5 |
36.1 |
0.70 |
0.67 |
3.9ms |
7.81ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-XS |
416*416 |
26.2 |
39.3 |
0.70 |
1.13 |
6.1ms |
12.38ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-S |
320*320 |
29.1 |
43.4 |
1.18 |
0.97 |
4.8ms |
9.56ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-S |
416*416 |
32.5 |
47.6 |
1.18 |
1.65 |
6.6ms |
15.20ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-M |
320*320 |
34.4 |
50.0 |
3.46 |
2.57 |
8.2ms |
17.68ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-M |
416*416 |
37.5 |
53.4 |
3.46 |
4.34 |
12.7ms |
28.39ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-L |
320*320 |
36.1 |
52.0 |
5.80 |
4.20 |
11.5ms |
25.21ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-L |
416*416 |
39.4 |
55.7 |
5.80 |
7.10 |
20.7ms |
42.23ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
PicoDet-L |
640*640 |
42.6 |
59.2 |
5.80 |
16.81 |
62.5ms |
108.1ms |
model | log |
config |
w/ 后处理 | w/o 后处理 |
|
|---|
| 模型 | 输入尺寸 | mAPval 0.5:0.95 | mAPval 0.5 | 参数量 (M) | FLOPS (G) | 预测时延NCNN (ms) |
|---|---|---|---|---|---|---|
| YOLOv3-Tiny | 416*416 | 16.6 | 33.1 | 8.86 | 5.62 | 25.42 |
| YOLOv4-Tiny | 416*416 | 21.7 | 40.2 | 6.06 | 6.96 | 23.69 |
| PP-YOLO-Tiny | 320*320 | 20.6 | - | 1.08 | 0.58 | 6.75 |
| PP-YOLO-Tiny | 416*416 | 22.7 | - | 1.08 | 1.02 | 10.48 |
| Nanodet-M | 320*320 | 20.6 | - | 0.95 | 0.72 | 8.71 |
| Nanodet-M | 416*416 | 23.5 | - | 0.95 | 1.2 | 13.35 |
| Nanodet-M 1.5x | 416*416 | 26.8 | - | 2.08 | 2.42 | 15.83 |
| YOLOX-Nano | 416*416 | 25.8 | - | 0.91 | 1.08 | 19.23 |
| YOLOX-Tiny | 416*416 | 32.8 | - | 5.06 | 6.45 | 32.77 |
| YOLOv5n | 640*640 | 28.4 | 46.0 | 1.9 | 4.5 | 40.35 |
| YOLOv5s | 640*640 | 37.2 | 56.0 | 7.2 | 16.5 | 78.05 |
| 模型 | 输入尺寸 | ONNX( w/o 后处理) | Paddle Lite(fp32) | Paddle Lite(fp16) |
|---|---|---|---|---|
| PicoDet-XS | 320*320 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-XS | 416*416 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-S | 320*320 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-S | 416*416 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-M | 320*320 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-M | 416*416 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-L | 320*320 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-L | 416*416 | ( w/ 后处理) | ( w/o 后处理) | model | model |
| PicoDet-L | 640*640 | ( w/ 后处理) | ( w/o 后处理) | model | model |
部署
| 预测库 | Python | C++ | 带后处理预测 |
|---|---|---|---|
| OpenVINO | Python | C++(带后处理开发中) | ✔︎ |
| Paddle Lite | - | C++ | ✔︎ |
| Android Demo | - | Paddle Lite | ✔︎ |
| PaddleInference | Python | C++ | ✔︎ |
| ONNXRuntime | Python | Coming soon | ✔︎ |
| NCNN | Coming soon | C++ | ✘ |
| MNN | Coming soon | C++ | ✘ |
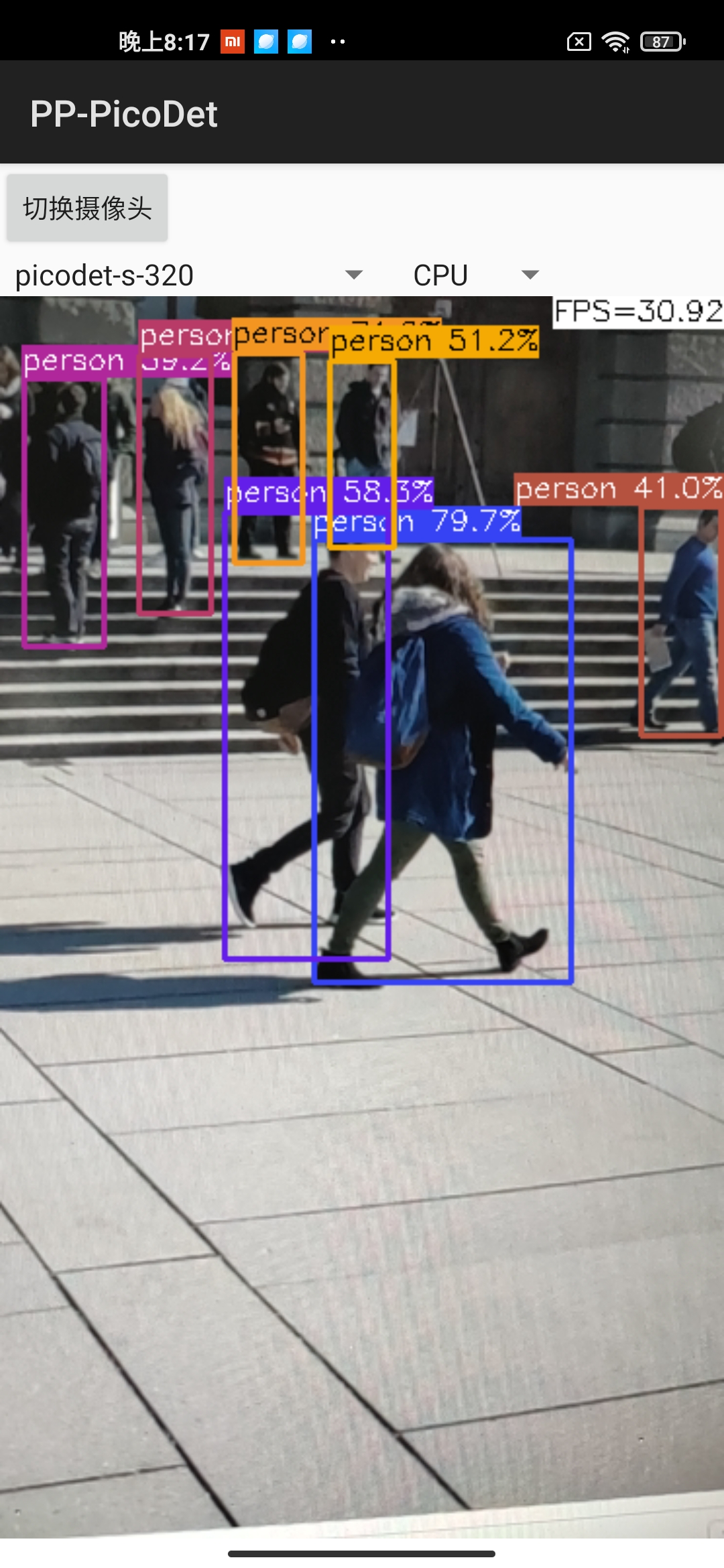
Android demo可视化:



量化
依赖包:
- PaddlePaddle >= 2.2.2
- PaddleSlim >= 2.2.2
安装:
pip install paddleslim==2.2.2
量化训练
开始量化训练:
python tools/train.py -c configs/picodet/picodet_s_416_coco_lcnet.yml \
--slim_config configs/slim/quant/picodet_s_416_lcnet_quant.yml --eval
- 更多细节请参考slim文档
- 量化训练Model ZOO:
| 量化模型 | 输入尺寸 | mAPval 0.5:0.95 | Configs | Weight | Inference Model | Paddle Lite(INT8) |
|---|---|---|---|---|---|---|
| PicoDet-S | 416*416 | 31.5 | config | slim config | model | w/ 后处理 | w/o 后处理 | w/ 后处理 | w/o 后处理 |