
 zhengbochao
72ce31fb2f
create README.md
zhengbochao
72ce31fb2f
create README.md
|
před 6 měsíci | |
|---|---|---|
| .. | ||
| apex | před 6 měsíci | |
| configs | před 6 měsíci | |
| data | před 6 měsíci | |
| figures | před 6 měsíci | |
| imagemet | před 6 měsíci | |
| kernels | před 6 měsíci | |
| models | před 6 měsíci | |
| output | před 6 měsíci | |
| .gitignore | před 6 měsíci | |
| CODE_OF_CONDUCT.md | před 6 měsíci | |
| LICENSE | před 6 měsíci | |
| MODELHUB.md | před 6 měsíci | |
| README.md | před 6 měsíci | |
| SECURITY.md | před 6 měsíci | |
| SUPPORT.md | před 6 měsíci | |
| __init__.py | před 6 měsíci | |
| config.py | před 6 měsíci | |
| demo.py | před 6 měsíci | |
| get_started.md | před 6 měsíci | |
| key.txt | před 6 měsíci | |
| logger.py | před 6 měsíci | |
| lr_scheduler.py | před 6 měsíci | |
| main.py | před 6 měsíci | |
| main_moe.py | před 6 měsíci | |
| main_simmim_ft.py | před 6 měsíci | |
| main_simmim_pt.py | před 6 měsíci | |
| main_test.py | před 6 měsíci | |
| optimizer.py | před 6 měsíci | |
| swin_tiny_patch4_window7_224.pth | před 6 měsíci | |
| utils.py | před 6 měsíci | |
| utils_moe.py | před 6 měsíci | |
| utils_simmim.py | před 6 měsíci | |
README.md
Swin Transformer




This repo is the official implementation of "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" as well as the follow-ups. It currently includes code and models for the following tasks:
Image Classification: Included in this repo. See get_started.md for a quick start.
Object Detection and Instance Segmentation: See Swin Transformer for Object Detection.
Semantic Segmentation: See Swin Transformer for Semantic Segmentation.
Video Action Recognition: See Video Swin Transformer.
Semi-Supervised Object Detection: See Soft Teacher.
SSL: Contrasitive Learning: See Transformer-SSL.
SSL: Masked Image Modeling: See get_started.md#simmim-support.
Mixture-of-Experts: See get_started for more instructions.
Feature-Distillation: See Feature-Distillation.
Updates
12/29/2022
- Nvidia's FasterTransformer now supports Swin Transformer V2 inference, which have significant speed improvements on
T4 and A100 GPUs.
11/30/2022
- Models and codes of Feature Distillation are released. Please refer to Feature-Distillation for details, and the checkpoints (FD-EsViT-Swin-B, FD-DeiT-ViT-B, FD-DINO-ViT-B, FD-CLIP-ViT-B, FD-CLIP-ViT-L).
09/24/2022
Merged SimMIM, which is a Masked Image Modeling based pre-training approach applicable to Swin and SwinV2 (and also applicable for ViT and ResNet). Please refer to get started with SimMIM to play with SimMIM pre-training.
Released a series of Swin and SwinV2 models pre-trained using the SimMIM approach (see MODELHUB for SimMIM), with model size ranging from SwinV2-Small-50M to SwinV2-giant-1B, data size ranging from ImageNet-1K-10% to ImageNet-22K, and iterations from 125k to 500k. You may leverage these models to study the properties of MIM methods. Please look into the data scaling paper for more details.
07/09/2022
News:
- SwinV2-G achieves
61.4 mIoUon ADE20K semantic segmentation (+1.5 mIoU over the previous SwinV2-G model), using an additional feature distillation (FD) approach, setting a new recrod on this benchmark. FD is an approach that can generally improve the fine-tuning performance of various pre-trained models, including DeiT, DINO, and CLIP. Particularly, it improves CLIP pre-trained ViT-L by +1.6% to reach89.0%on ImageNet-1K image classification, which is the most accurate ViT-L model. - Merged a PR from Nvidia that links to faster Swin Transformer inference that have significant speed improvements on
T4 and A100 GPUs. - Merged a PR from Nvidia that enables an option to use
pure FP16 (Apex O2)in training, while almost maintaining the accuracy.
06/03/2022
- Added Swin-MoE, the Mixture-of-Experts variant of Swin Transformer implemented using Tutel (an optimized Mixture-of-Experts implementation). Swin-MoE is introduced in the TuTel paper.
05/12/2022
- Pretrained models of Swin Transformer V2 on ImageNet-1K and ImageNet-22K are released.
- ImageNet-22K pretrained models for Swin-V1-Tiny and Swin-V2-Small are released.
03/02/2022
- Swin Transformer V2 and SimMIM got accepted by CVPR 2022. SimMIM is a self-supervised pre-training approach based on masked image modeling, a key technique that works out the 3-billion-parameter Swin V2 model using
40x less labelled datathan that of previous billion-scale models based on JFT-3B.
02/09/2022
- Integrated into Huggingface Spaces 🤗 using Gradio. Try out the Web Demo
10/12/2021
- Swin Transformer received ICCV 2021 best paper award (Marr Prize).
08/09/2021
- Soft Teacher will appear at ICCV2021. The code will be released at GitHub Repo.
Soft Teacheris an end-to-end semi-supervisd object detection method, achieving a new record on the COCO test-dev:61.3 box APand53.0 mask AP.
07/03/2021
- Add Swin MLP, which is an adaption of
Swin Transformerby replacing all multi-head self-attention (MHSA) blocks by MLP layers (more precisely it is a group linear layer). The shifted window configuration can also significantly improve the performance of vanilla MLP architectures.
06/25/2021
- Video Swin Transformer is released at Video-Swin-Transformer.
Video Swin Transformerachieves state-of-the-art accuracy on a broad range of video recognition benchmarks, including action recognition (84.9top-1 accuracy on Kinetics-400 and86.1top-1 accuracy on Kinetics-600 with~20xless pre-training data and~3xsmaller model size) and temporal modeling (69.6top-1 accuracy on Something-Something v2).
05/12/2021
- Used as a backbone for
Self-Supervised Learning: Transformer-SSL
Using Swin-Transformer as the backbone for self-supervised learning enables us to evaluate the transferring performance of the learnt representations on down-stream tasks, which is missing in previous works due to the use of ViT/DeiT, which has not been well tamed for down-stream tasks.
04/12/2021
Initial commits:
- Pretrained models on ImageNet-1K (Swin-T-IN1K, Swin-S-IN1K, Swin-B-IN1K) and ImageNet-22K (Swin-B-IN22K, Swin-L-IN22K) are provided.
- The supported code and models for ImageNet-1K image classification, COCO object detection and ADE20K semantic segmentation are provided.
- The cuda kernel implementation for the local relation layer is provided in branch LR-Net.
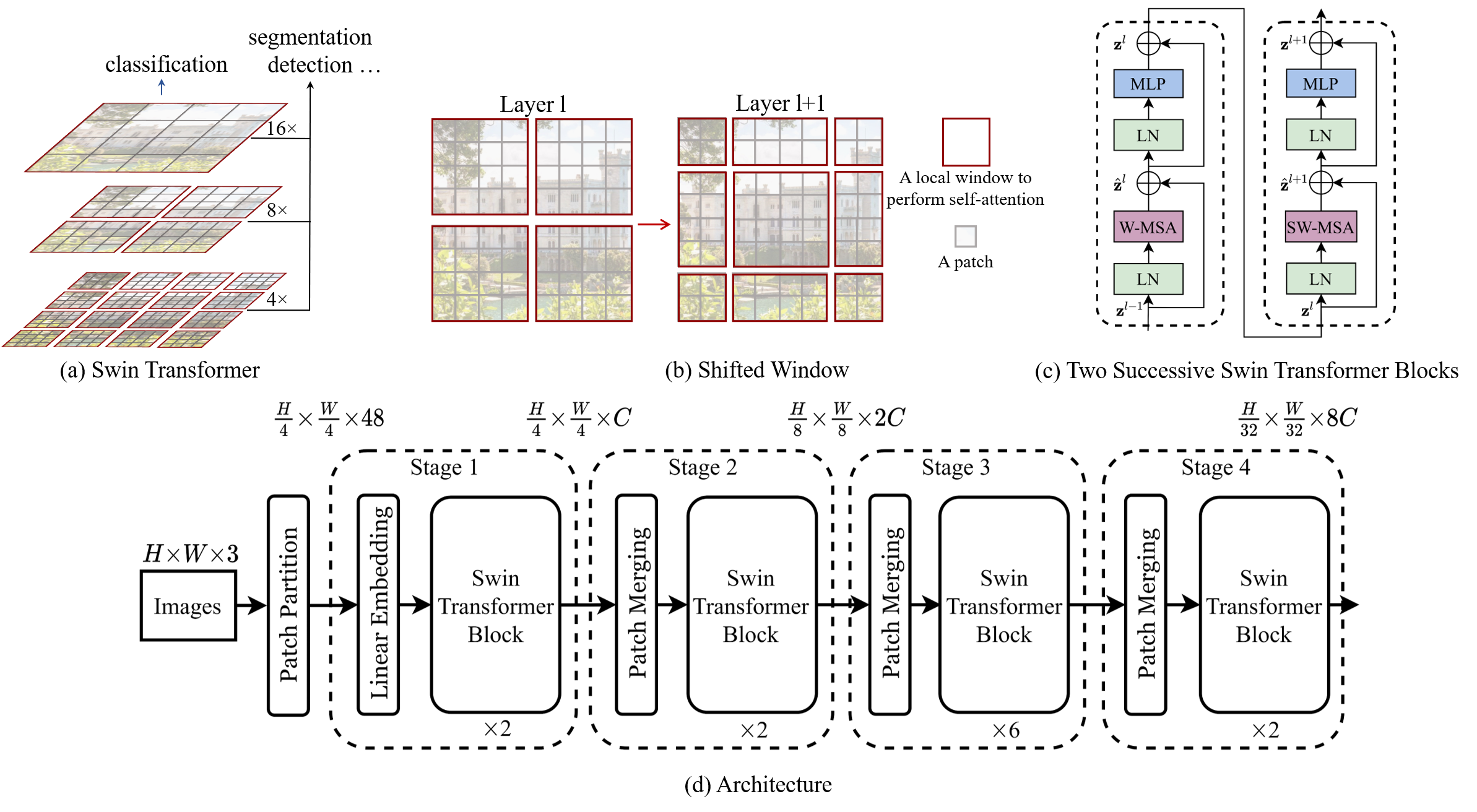
Introduction
Swin Transformer (the name Swin stands for Shifted window) is initially described in arxiv, which capably serves as a
general-purpose backbone for computer vision. It is basically a hierarchical Transformer whose representation is
computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention
computation to non-overlapping local windows while also allowing for cross-window connection.
Swin Transformer achieves strong performance on COCO object detection (58.7 box AP and 51.1 mask AP on test-dev) and
ADE20K semantic segmentation (53.5 mIoU on val), surpassing previous models by a large margin.
Main Results on ImageNet with Pretrained Models
ImageNet-1K and ImageNet-22K Pretrained Swin-V1 Models
| name | pretrain | resolution | acc@1 | acc@5 | #params | FLOPs | FPS | 22K model | 1K model |
|---|---|---|---|---|---|---|---|---|---|
| Swin-T | ImageNet-1K | 224x224 | 81.2 | 95.5 | 28M | 4.5G | 755 | - | github/baidu/config/log |
| Swin-S | ImageNet-1K | 224x224 | 83.2 | 96.2 | 50M | 8.7G | 437 | - | github/baidu/config/log |
| Swin-B | ImageNet-1K | 224x224 | 83.5 | 96.5 | 88M | 15.4G | 278 | - | github/baidu/config/log |
| Swin-B | ImageNet-1K | 384x384 | 84.5 | 97.0 | 88M | 47.1G | 85 | - | github/baidu/config |
| Swin-T | ImageNet-22K | 224x224 | 80.9 | 96.0 | 28M | 4.5G | 755 | github/baidu/config | github/baidu/config |
| Swin-S | ImageNet-22K | 224x224 | 83.2 | 97.0 | 50M | 8.7G | 437 | github/baidu/config | github/baidu/config |
| Swin-B | ImageNet-22K | 224x224 | 85.2 | 97.5 | 88M | 15.4G | 278 | github/baidu/config | github/baidu/config |
| Swin-B | ImageNet-22K | 384x384 | 86.4 | 98.0 | 88M | 47.1G | 85 | github/baidu | github/baidu/config |
| Swin-L | ImageNet-22K | 224x224 | 86.3 | 97.9 | 197M | 34.5G | 141 | github/baidu/config | github/baidu/config |
| Swin-L | ImageNet-22K | 384x384 | 87.3 | 98.2 | 197M | 103.9G | 42 | github/baidu | github/baidu/config |
ImageNet-1K and ImageNet-22K Pretrained Swin-V2 Models
| name | pretrain | resolution | window | acc@1 | acc@5 | #params | FLOPs | FPS | 22K model | 1K model |
|---|---|---|---|---|---|---|---|---|---|---|
| SwinV2-T | ImageNet-1K | 256x256 | 8x8 | 81.8 | 95.9 | 28M | 5.9G | 572 | - | github/baidu/config |
| SwinV2-S | ImageNet-1K | 256x256 | 8x8 | 83.7 | 96.6 | 50M | 11.5G | 327 | - | github/baidu/config |
| SwinV2-B | ImageNet-1K | 256x256 | 8x8 | 84.2 | 96.9 | 88M | 20.3G | 217 | - | github/baidu/config |
| SwinV2-T | ImageNet-1K | 256x256 | 16x16 | 82.8 | 96.2 | 28M | 6.6G | 437 | - | github/baidu/config |
| SwinV2-S | ImageNet-1K | 256x256 | 16x16 | 84.1 | 96.8 | 50M | 12.6G | 257 | - | github/baidu/config |
| SwinV2-B | ImageNet-1K | 256x256 | 16x16 | 84.6 | 97.0 | 88M | 21.8G | 174 | - | github/baidu/config |
| SwinV2-B* | ImageNet-22K | 256x256 | 16x16 | 86.2 | 97.9 | 88M | 21.8G | 174 | github/baidu/config | github/baidu/config |
| SwinV2-B* | ImageNet-22K | 384x384 | 24x24 | 87.1 | 98.2 | 88M | 54.7G | 57 | github/baidu/config | github/baidu/config |
| SwinV2-L* | ImageNet-22K | 256x256 | 16x16 | 86.9 | 98.0 | 197M | 47.5G | 95 | github/baidu/config | github/baidu/config |
| SwinV2-L* | ImageNet-22K | 384x384 | 24x24 | 87.6 | 98.3 | 197M | 115.4G | 33 | github/baidu/config | github/baidu/config |
Note:
- SwinV2-B* (SwinV2-L*) with input resolution of 256x256 and 384x384 both fine-tuned from the same pre-training model using a smaller input resolution of 192x192.
- SwinV2-B* (384x384) achieves 78.08 acc@1 on ImageNet-1K-V2 while SwinV2-L* (384x384) achieves 78.31.
ImageNet-1K Pretrained Swin MLP Models
| name | pretrain | resolution | acc@1 | acc@5 | #params | FLOPs | FPS | 1K model |
|---|---|---|---|---|---|---|---|---|
| Mixer-B/16 | ImageNet-1K | 224x224 | 76.4 | - | 59M | 12.7G | - | official repo |
| ResMLP-S24 | ImageNet-1K | 224x224 | 79.4 | - | 30M | 6.0G | 715 | timm |
| ResMLP-B24 | ImageNet-1K | 224x224 | 81.0 | - | 116M | 23.0G | 231 | timm |
| Swin-T/C24 | ImageNet-1K | 256x256 | 81.6 | 95.7 | 28M | 5.9G | 563 | github/baidu/config |
| SwinMLP-T/C24 | ImageNet-1K | 256x256 | 79.4 | 94.6 | 20M | 4.0G | 807 | github/baidu/config |
| SwinMLP-T/C12 | ImageNet-1K | 256x256 | 79.6 | 94.7 | 21M | 4.0G | 792 | github/baidu/config |
| SwinMLP-T/C6 | ImageNet-1K | 256x256 | 79.7 | 94.9 | 23M | 4.0G | 766 | github/baidu/config |
| SwinMLP-B | ImageNet-1K | 224x224 | 81.3 | 95.3 | 61M | 10.4G | 409 | github/baidu/config |
Note: access code for baidu is swin. C24 means each head has 24 channels.
ImageNet-22K Pretrained Swin-MoE Models
- Please refer to get_started for instructions on running Swin-MoE.
- Pretrained models for Swin-MoE can be found in MODEL HUB
Main Results on Downstream Tasks
COCO Object Detection (2017 val)
| Backbone | Method | pretrain | Lr Schd | box mAP | mask mAP | #params | FLOPs |
|---|---|---|---|---|---|---|---|
| Swin-T | Mask R-CNN | ImageNet-1K | 3x | 46.0 | 41.6 | 48M | 267G |
| Swin-S | Mask R-CNN | ImageNet-1K | 3x | 48.5 | 43.3 | 69M | 359G |
| Swin-T | Cascade Mask R-CNN | ImageNet-1K | 3x | 50.4 | 43.7 | 86M | 745G |
| Swin-S | Cascade Mask R-CNN | ImageNet-1K | 3x | 51.9 | 45.0 | 107M | 838G |
| Swin-B | Cascade Mask R-CNN | ImageNet-1K | 3x | 51.9 | 45.0 | 145M | 982G |
| Swin-T | RepPoints V2 | ImageNet-1K | 3x | 50.0 | - | 45M | 283G |
| Swin-T | Mask RepPoints V2 | ImageNet-1K | 3x | 50.3 | 43.6 | 47M | 292G |
| Swin-B | HTC++ | ImageNet-22K | 6x | 56.4 | 49.1 | 160M | 1043G |
| Swin-L | HTC++ | ImageNet-22K | 3x | 57.1 | 49.5 | 284M | 1470G |
| Swin-L | HTC++* | ImageNet-22K | 3x | 58.0 | 50.4 | 284M | - |
Note: * indicates multi-scale testing.
ADE20K Semantic Segmentation (val)
| Backbone | Method | pretrain | Crop Size | Lr Schd | mIoU | mIoU (ms+flip) | #params | FLOPs |
|---|---|---|---|---|---|---|---|---|
| Swin-T | UPerNet | ImageNet-1K | 512x512 | 160K | 44.51 | 45.81 | 60M | 945G |
| Swin-S | UperNet | ImageNet-1K | 512x512 | 160K | 47.64 | 49.47 | 81M | 1038G |
| Swin-B | UperNet | ImageNet-1K | 512x512 | 160K | 48.13 | 49.72 | 121M | 1188G |
| Swin-B | UPerNet | ImageNet-22K | 640x640 | 160K | 50.04 | 51.66 | 121M | 1841G |
| Swin-L | UperNet | ImageNet-22K | 640x640 | 160K | 52.05 | 53.53 | 234M | 3230G |
Citing Swin Transformer
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
Citing Local Relation Networks (the first full-attention visual backbone)
@inproceedings{hu2019local,
title={Local Relation Networks for Image Recognition},
author={Hu, Han and Zhang, Zheng and Xie, Zhenda and Lin, Stephen},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages={3464--3473},
year={2019}
}
Citing Swin Transformer V2
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
Citing SimMIM (a self-supervised approach that enables SwinV2-G)
@inproceedings{xie2021simmim,
title={SimMIM: A Simple Framework for Masked Image Modeling},
author={Xie, Zhenda and Zhang, Zheng and Cao, Yue and Lin, Yutong and Bao, Jianmin and Yao, Zhuliang and Dai, Qi and Hu, Han},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
Citing SimMIM-data-scaling
@article{xie2022data,
title={On Data Scaling in Masked Image Modeling},
author={Xie, Zhenda and Zhang, Zheng and Cao, Yue and Lin, Yutong and Wei, Yixuan and Dai, Qi and Hu, Han},
journal={arXiv preprint arXiv:2206.04664},
year={2022}
}
Citing Swin-MoE
@misc{hwang2022tutel,
title={Tutel: Adaptive Mixture-of-Experts at Scale},
author={Changho Hwang and Wei Cui and Yifan Xiong and Ziyue Yang and Ze Liu and Han Hu and Zilong Wang and Rafael Salas and Jithin Jose and Prabhat Ram and Joe Chau and Peng Cheng and Fan Yang and Mao Yang and Yongqiang Xiong},
year={2022},
eprint={2206.03382},
archivePrefix={arXiv}
}
Getting Started
- For Image Classification, please see get_started.md for detailed instructions.
- For Object Detection and Instance Segmentation, please see Swin Transformer for Object Detection.
- For Semantic Segmentation, please see Swin Transformer for Semantic Segmentation.
- For Self-Supervised Learning, please see Transformer-SSL.
- For Video Recognition, please see Video Swin Transformer.
Third-party Usage and Experiments
In this pargraph, we cross link third-party repositories which use Swin and report results. You can let us know by raising an issue
(Note please report accuracy numbers and provide trained models in your new repository to facilitate others to get sense of correctness and model behavior)
[12/29/2022] Swin Transformers (V2) inference implemented in FasterTransformer: FasterTransformer
[06/30/2022] Swin Transformers (V1) inference implemented in FasterTransformer: FasterTransformer
[05/12/2022] Swin Transformers (V1) implemented in TensorFlow with the pre-trained parameters ported into them. Find the implementation, TensorFlow weights, code example here in this repository.
[04/06/2022] Swin Transformer for Audio Classification: Hierarchical Token Semantic Audio Transformer.
[12/21/2021] Swin Transformer for StyleGAN: StyleSwin
[12/13/2021] Swin Transformer for Face Recognition: FaceX-Zoo
[08/29/2021] Swin Transformer for Image Restoration: SwinIR
[08/12/2021] Swin Transformer for person reID: https://github.com/layumi/Person_reID_baseline_pytorch
[06/29/2021] Swin-Transformer in PaddleClas and inference based on whl package: https://github.com/PaddlePaddle/PaddleClas
[04/14/2021] Swin for RetinaNet in Detectron: https://github.com/xiaohu2015/SwinT_detectron2.
[04/16/2021] Included in a famous model zoo: https://github.com/rwightman/pytorch-image-models.
[04/20/2021] Swin-Transformer classifier inference using TorchServe: https://github.com/kamalkraj/Swin-Transformer-Serve
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.